
Supervised learning (지도학습 분석기법)
1. Dedision Tree (의사결정나무)
데이터 분류, 예측 -> 도표화
장점)
1. IF THEN 형태 표현 : 결과 이해 / 해석 용이
2. 통계적 가정 필요X
3. 분류 과정 -> 변수 중요도 파악 가능
단점)
1. 적합 모형 만듦 -> 시간 소요 多
2. 변수 간 상관성 파악 어려움 (∵각각 하나의 변수 기준 구분)
Data Set : Titanic training (생존요인 관련 속성만 포함)


생존확률에 가장 큰 영향 미치는 속성 : 성별 > 승선한 부모/자녀 수 > 승선한 형제자매/배우자 수 > Passenger Fare 순
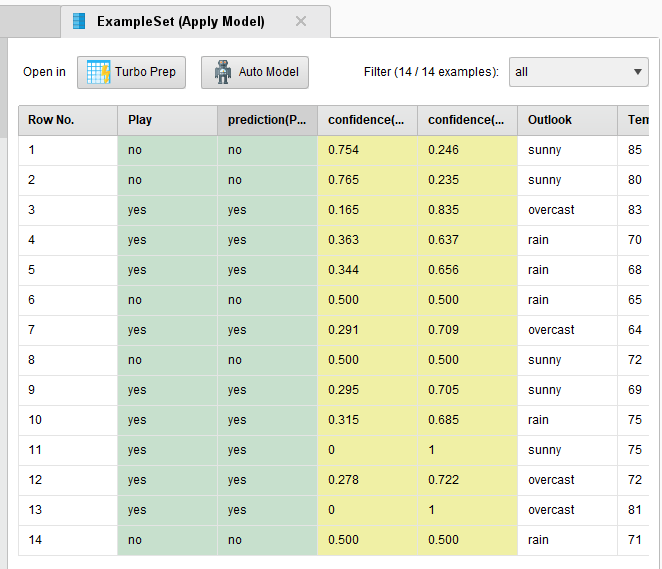
2. K-NN (K-Nearest Neighbor / 최근접 이웃 알고리즘)
New data - Nearest data : 새로운 데이터가 속하는 그룹 예측
Data Set : Golf
온도, 습도, 바람, 날씨 등 기준 -> 골프 play 여부 분류 데이터

3. Regression Analysis (회귀 분석)
변수 간 상호 관련성 규명, X(독립변수)-Y(종속변수) 변화 예측
종류 : 단순 회귀 분석, 다중 회귀 분석, 로지스틱 회귀 분석
A) Simple Linear Regression Model (단순 회귀 분석)
X : 1 -> X-Y 선형관계 분석
B) Multiple Linear Regression Model (다중 회귀 분석)
X1, X2, X3 -> Y
Data Set : Polynomial / 1-5 공정 측정값(X) & 종합검사 결과 label(Y)


a1 ~ a4 : X-Y는 +선형관계
a5 : -선형관계
p-value)
a1 ~ a3, a5 : 0.05 ↓ 통계적으로 유의함
a4 : 0.05 ↑ 유의하지 않음
Linear Discriminant Analysis (판별 분석)
| (2개 ↑)모집단으로부터 표본 섞여 있을 때 |
| 각각 Case 대해 |
| 어느 모집단에 속해 있는지 판별 |
| (함수 생성) 판별 작업 실시 |
| EX) 생맥주 컵에 든 맥주 마셔서 맥주이름 알아맞힐 때, 거품 형태 / 쓴맛 정도 / 색깔 -> (판별) : 결과 |
판별 분석 목적)
1. Y 분류에 도움 되는 X 선정
2. 선정된 X 이용 -> 판별 함수 도출
3. 판별 능력 대한 X -> 상대적 중요도 평가
4. 판별 함수 -> 판별 능력 평가
5. New 판별 대상 -> 예측력 평가
1. LDA (Linear Discriminant Analysis)
Data Set : Sonar
多 광석 -> 실제 광석 / 일반 돌 추측 분류

Operator)
LDA : 집단 구분 가능 설명변수 -> 선형판별함수 도출 -> 소속 집단 예측
Apply Model : 목표 변수 실제값 & 분류된 값 비교

실제값 / 예측값 비교
'[Data Science] > Data Analysis' 카테고리의 다른 글
| [Bike Sharing Demand]비즈니스 이해 - Washington D.C. (0) | 2022.04.20 |
|---|---|
| [Bike Sharing Demand]비즈니스 이해 - 두서없이 찾은 자료 나열 (0) | 2022.04.19 |
| CRISP-DM (0) | 2022.04.15 |
| [미완성]Titanic Date 전처리 (0) | 2022.04.11 |
| Unsupervised Learning (0) | 2022.03.28 |