
RapidMiner 프로그램을 이용할 예정이다.
GUI 형식으로 되어 있어 데이터 분석 초보자가 사용하기에 편리하다는 이점이 있다.
1. 데이터 전처리
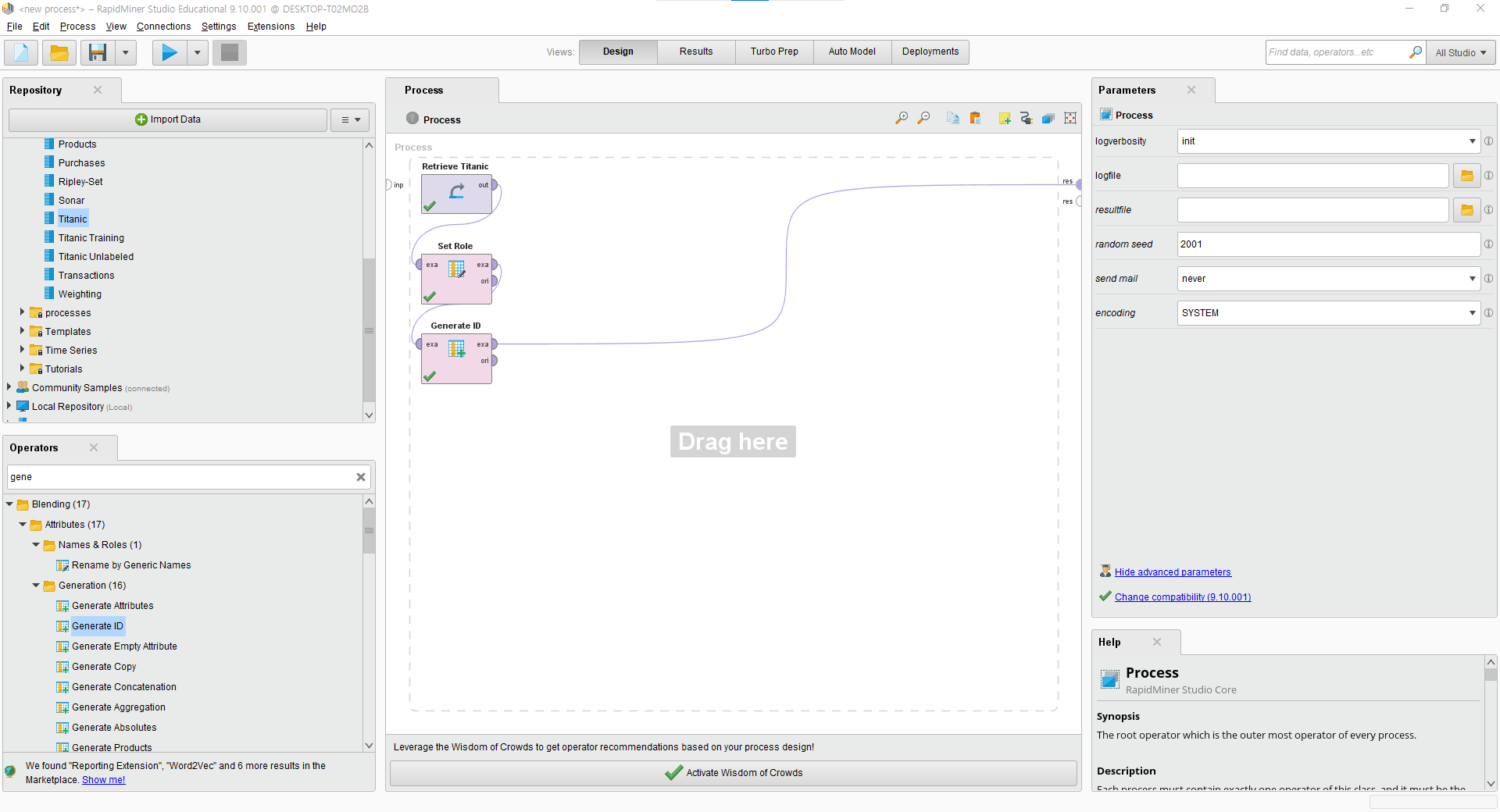
-타이타닉 데이터를 Process 창에 끌어다 놓으면 [Retrieve Titanic] 박스가 생성된다.
💡 Retrieve : 회수하다, (정보를) 검색하다
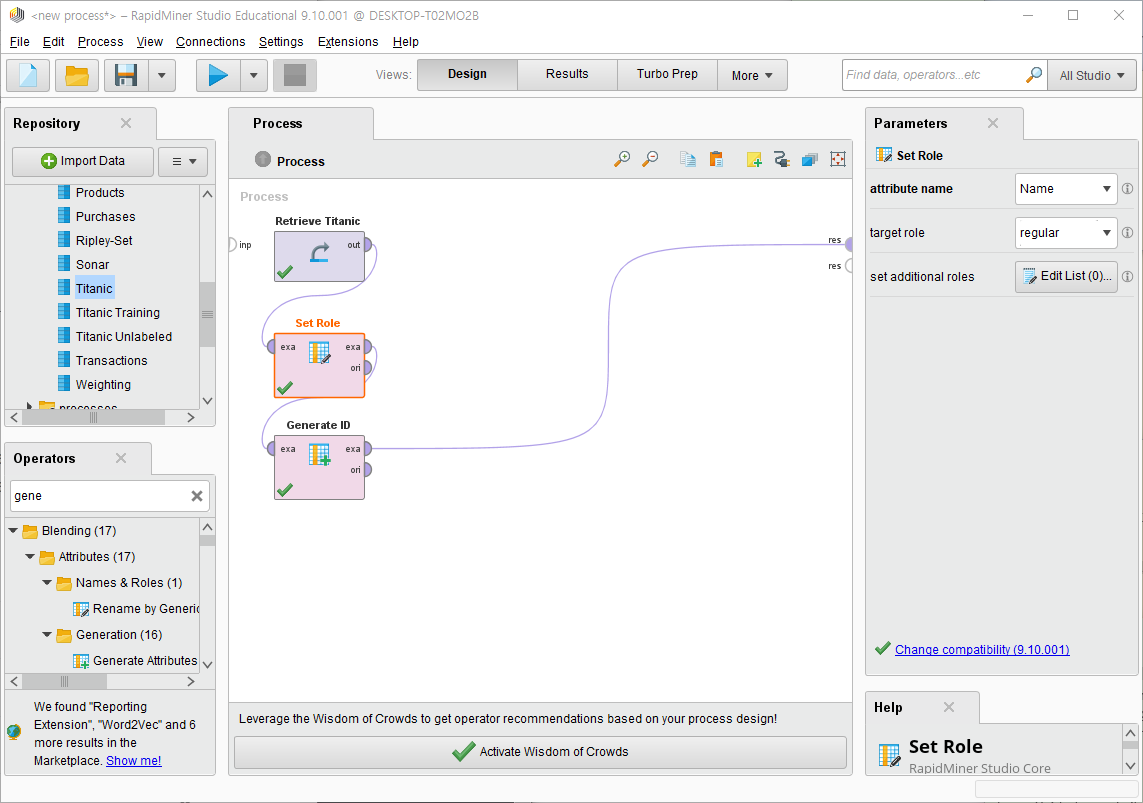
set role operator을 배치해주고 파라미터 내 attribute name(속성 이름)을 정해준다.
이름으로 정해줬다.
▶attribute name 설명
attribute name
Description:
The name of the Attribute which role should be changed.
The name can be selected from the dropdown menu or manual typed.
Range: string
Optional: false
속성 이름
설명:
(특성의 이름/역할이 바뀌어야 하는)
역할이 바뀌어야 하는 특성의 이름이다.
(이름은 선택될 수 있다/드롭다운 메뉴에서부터/혹은/수동으로 입력할 수 있다)
이름은 드롭다운 메뉴로부터 선택되거나 수동으로 입력 가능하다.
범위: 문자열
선택 사항: false
💡 manual : 설명서, 수동으로
▶target role 설명
target role
Description:
The target role of the selected Attribute is the new role assigned to it. Following target roles are possible:
▶regular: Attributes without a special role. Regular Attributes are used as input variables for learning tasks.
▶id: This is a special role. An Attribute with the id role acts as an identifier for the Examples. It should be unique for all Examples. Different Blending Operators (Join, Union, Transpose, Pivot, ...) uses the id Attribute to perform their tasks.
▶label: This is a special role. An Attribute with the label role acts as a target Attribute for learning Operators. The label is also often called 'target variable' or 'class'.
▶prediction: This is a special role. An Attribute with the prediction role is the result of an application of a learning model. The Apply Model Operator adds for example a prediction Attribute to the ExampleSet. To evaluate the performance of a model, a label and a prediction Attribute is necessary.
▶cluster: This is a special role. An Attribute with the cluster role indicates the membership of an ExampleSet to a particular cluster. For example the k-Means Operator adds an Attribute with the cluster role.
▶weight: This is a special role. An Attribute with the weight role indicates the weight of the Examples with regard to the label. Weights are used in learning processes to set the importance of Examples. Weights can also be used to evaluate the performance of models; there they assign a severness for misclassification of single Examples.
▶batch: This is a special role. An Attribute with the batch role indicates the memebership to a specific batch.
▶user defined: Any role can be assigned to an Attribute by typing in the textbox. User defined roles are special roles, so one specific role cannot be assigned to more than one Attribute. Attributes with user defined roles are ignored in learning processes. So an Attribute with a user defined role is ignored in a learning processes but remains in the ExampleSet.
Range: regular, id, label, prediction, cluster, weight, batch; default: 'regular'
Optional: true
목표물 역할
설명:
(선택된 속성의 타겟 역할은 새로운 역할이다/그것에 할당된)
선택된 속성의 타겟 역할은 그 속성에 할당된 새로운 역할이다.
(다음으론 타겟 역할들이 가능한 것이다.)
다음과 같은 대상 역할 수행 가능하다:
▶정규: 특별한 역할 없는 속성. 정규 속성은 학습 업무들의 입력 변수로 사용된다.
▶id: 이건 특별한 역할이다. id 역할이 있는 속성은 예제에 대해서 식별자도 활동한다.
그것은 모든 예제에 대해 고유해야 한다. 다른 혼합 연산자(결합, 조합, 이동, 회전..)들은 id 속성을 이용해서 그들의 업무를 수행한다.
▶label: 특별한 역할이다. label 역할이 있는 속성은 학습 연산자에 대해 타겟 속성으로 활동한다.
이 label은 또한 자주 '타겟 변수' 혹은 '클래스'로 불리운다.
▶예측: 특별한 역할이다. 예측 역할이 있는 속성은 학습 모델의 적용 결과다. 모델 적용 연산자는 예를 들어서 예측 속성을 예제 집합에 추가한다. 모델의 성능을 평가하기 위해서, label과 예측 속성은 필요하다.
▶클러스터: 특별한 역할이다. 클러스터 역할이 있는 속성은 특정 클러스터로 설정하기 위해 예제의 멤버 자격을 나타낸다. 예를 들어 k-평균 연산자는 클러스터 역할이 있는 속성을 추가한다.
▶가중치: 특별한 역할이다. 가중치 역할이 있는 속성은 label에 대한 예제 가중치를 나타낸다.
가중치는 중요한 예제를 설정하기 위해 학습 프로세스에 사용된다. 가중치는 또한 모델의 성능을 평가하는데 사용될 수 있다; 그들은 단일 예제의 분류오류에 대해 심각성을 할당한다.
▶함께 묶음: 특별한 역할. batch 역할이 있는 속성은 특별한 batch에 대해서 멤버 자격을 나타낸다.
▶사용자 정의: 아무 역할은 텍스트 상자에 입력함으로써 속성에 할당될 수 있다. 정의된 사용자 역할은 특별한 역할인데 그래서 하나의 특별한 역할은 하나뿐 아니라, 많은 속성에 할당할 수 없다. 사용자 정의 역할이 있는 속성은 학습 프로세스에서 무시된다. 그래서 사용자 정의 역할이 있는 속성은 학습 프로세스에서 무시되지만 예제 집합에는 남아 있다.
범위: regular, id, label, prediction, cluster, weight, batch; default: 'regular'
선택사항: true
💡 assigned : 할당된
💡 identifier : 식별자
💡 union: 조합
💡 transpose: 이동하다
💡vpivot: (축을 중심으로)회전하다
💡 application: 응용, 적용
💡 evaluate: 평가하다
💡 vindicate: 나타내다
💡 particular: 자세한 사실, 서면 정보
💡 with regard to: ~에 관해서는
💡 assign : 맡기다, 배치하다
💡 misclassification: 분류오류
💡 severness: 심각성
💡 batch: (일괄 처리)함께 묶다
💡 more than one: 하나뿐 아니라, 많은
💡 remain: 남다
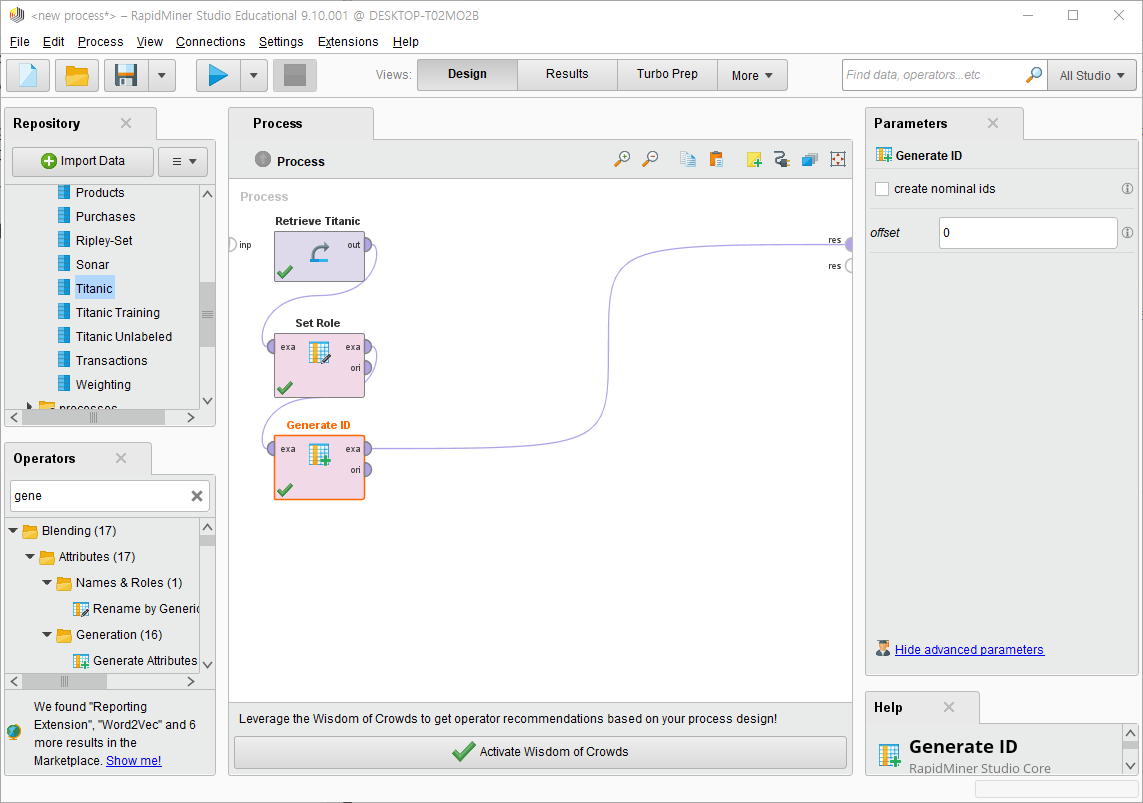
-[Generate ID] 데이터에 ID 부여
generate id operator를 사용해 고유 id를 생성한다. (수치형/명목형)
파라미터는 기본값으로 지정하였다.
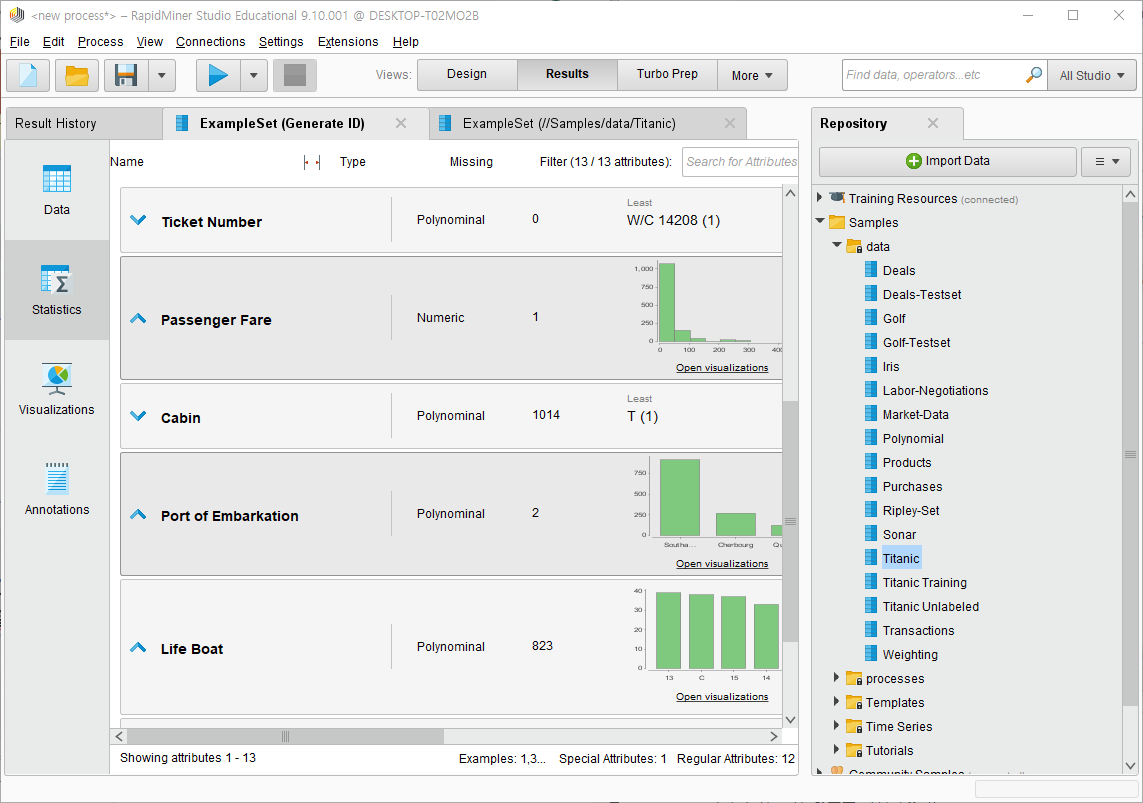
Passenger Fare, Port of Embarkation 부분에 결측치가 각각 1개, 2개씩 존재한다.
승객 요금, 승선항은 데이터 분석에 필요하지만 결측치가 있어 정확한 분석을 하기 어렵다.
따라서 row data는 제거한다.
💡 port: 항구 (도시)
💡 embarkation: 승선, 탑승
-Life Boat & Cabin은 생존 확률 예측에 활용도가 낮아 제외하고자 한다.


[Blending] - [Attributes] - [Selection] - Select Attributes Operator 사용
: 데이터 분석에 필요한 컬럼만 선택 가능
우측 파라미터)
attribute filter type : subset
attributes : cabin, life boat 선택
invert selection : check (cabin, life boat 선택 후 이 속성들만 제외하고 나머지 반영)
-> 해당 Operator 설정 완료하면 cabin, life boat 선택한 이 두 속성을 제외한 나머지 속성들이 보여진다.
▶attribute filter type 설명
attribute filter type
속성 필터 유형
Description:
설명:
This parameter allows you to select the Attribute selection filter; the method you want to use for selecting Attributes.
이 파라미터는 당신이 속성 선택 필터를 선택하는 것을 허용한다; 당신이 속성을 선택하는 것에 대해 사용하고자 하는 방법. 다음과 같은 옵션이 있다.
It has the following options:
그것은 다음과 같은 옵션을 가진다:
▶all: This option selects all the Attributes of the ExampleSet, no Attributes are removed.
▶all: 이 옵션은 예제의 속성들을 모두 선택하는데, 속성들은 제거되지 않는다.
This is the default option.
이것은 기본 옵션이다.
▶single: This option allows the selection of a single Attribute.
▶single: 이 옵션은 단일 속성을 선택하는 것을 허락한다.
The required Attribute is selected by the attribute parameter.
이러한 필수 속성은 속성 파라미터에 의해 선택된다.
▶subset: This option allows the selection of multiple Attributes through a list (see parameter attributes).
▶subset(하위 집합): 이 옵션은 목록을 통해 여러 속성의 선택을 허락한다(파라미터 속성을 보라).
If the meta data of the ExampleSet is known all Attributes are present in the list and the required ones can easily be selected.
예제의 메타 데이터의 경우, 모든 특성들은 목록에 존재하며 요구되는 것들은 쉽게 선택될 수 있다고 알려져 있다.
▶regular_expression: This option allows you to specify a regular expression for the Attribute selection.
▶regular_expression: 이 옵션은 속성 선택에 대한 구체적인 정규 표현을 허락한다.
The regular expression filter is configured by the parameters regular expression, use except expression and except expression.
정규 표현 필터는 파라미터 정규 표현로 형성화된다, 사용 예외 표현식과 예외 표현식.
▶value_type: This option allows selection of all the Attributes of a particular type.
▶value_type: 이 옵션은 자세한 타입의 모든 속성의 선택을 허락한다.
It should be noted that types are hierarchical.
그것은 타입들이 계층적이라는 것을 인지해야 한다.
For example real and integer types both belong to the numeric type.
예를 들어 실수와 정수 두 타입은 숫자 타입에 속한다.
The value type filter is configured by the parameters value type, use value type exception, except value type.
값 타입 필터는 파라미터(=매개 변수) 값 유형, 값 유형 예외 사용, 예외 값 유형으로 구성된다.
▶block_type: This option allows the selection of all the Attributes of a particular block type.
▶block_type: 이 옵션은 구체적인 블록 타입의 모든 속성의 선택을 허락한다.
It should be noted that block types may be hierarchical.
블록 타입들은 계층에 따른다는 것을 인지해야 한다.
For example value_series_start and value_series_end block types both belong to the value_series block type.
예를 들어 value_series_start와 value_series_end block types 둘 다 value_series block type에 속한다.
The block type filter is configured by the parameters block type, use block type exception, except block type.
블록 타입 필터는 매개 변수들의 블록 타입, 블록 타입 예외 사용, 예외 블록 타입으로 구성되었다.
▶no_missing_values: This option selects all Attributes of the ExampleSet which do not contain a missing value in any Example.
▶no_missing_values: 이 옵션은 어떤 예시 안애서 결측치를 포함하지 않는 예제의 모든 속성들을 선택한다.
Attributes that have even a single missing value are removed.
결측값이 하나라도 있는 속성들은 제거된다.
▶numeric_value_filter: All numeric Attributes whose Examples all match a given numeric condition are selected.
▶numeric_value_filter: 모든 숫자 속성들(예시들이 주어진 숫자 조건과 모두 일치하는)은 선택된다.
The condition is specified by the numeric condition parameter.
조건은 숫자 조건 매개 변수에 의해 명시되었다.
Please note that all nominal Attributes are also selected irrespective of the given numerical condition.
모든 명목 속성들 또한 주어진 숫자 조건에 개의치 않고 선택되어 진다는 것을 인지하여라.
Range: all, single, subset, regular_expression, value_type, block_type,
no_missing_values, numeric_value_filter; default: all
Optional: true
💡 subset : 하위 집합
💡 present : 존재하다
💡 expression : 표현, 표출
💡 specify : 구체적인
💡 be configured : 형상화되다
💡 configure : (컴퓨터) 환경을 설정하다
💡 particular : 자세한
💡 hierarchical : 계급, 계층에 따른
💡 be noted : 인지 (당)하다
💡 belong : 제자리에 있다, 소속감을 느끼다
💡 parameter : 매개 변수
💡 specify : (구체적으로) 명시하다
💡 nominal : 명목상의, 이름뿐인, 명사의
💡 irrespective : ~을 무시하고, ~에 개의치 않고(of)
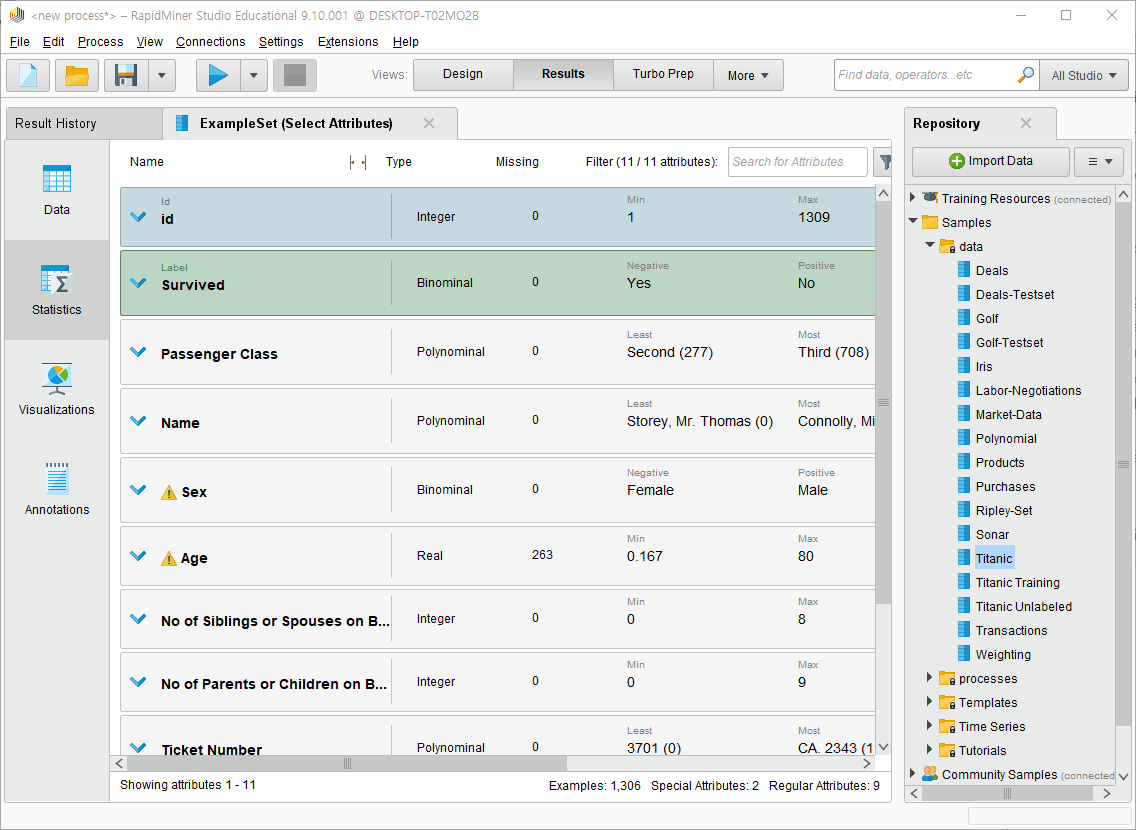
아래 화면을 보면 Age 내 수많은 결측치가 거슬린다.
하지만 나이는 생존 예측에 매우 중요한 요인이기 때문에 결측치들을 없앨 수 없다.
따라서 평균값으로 대체한다.
'[Data Science] > Data Analysis' 카테고리의 다른 글
| [Bike Sharing Demand]비즈니스 이해 - Washington D.C. (0) | 2022.04.20 |
|---|---|
| [Bike Sharing Demand]비즈니스 이해 - 두서없이 찾은 자료 나열 (0) | 2022.04.19 |
| CRISP-DM (0) | 2022.04.15 |
| Unsupervised Learning (0) | 2022.03.28 |
| Supervised learning (0) | 2022.03.28 |