
첫 ppt 발표 : 2022. 5. 2. 월요일
개선 ppt 발표 : 2022. 5. 23. 월요일
실제로 첫 프로젝트를 발표한지 두달이 지났지만 나의 변화를 보기 위해 올린다..^^
피드백과 개선사항 위주로 업로드하려고 한다.
1) PPT 퀄리티
1. 정말 조잡한 목차

모델링까지 완료해서 목차를 수정하였다.

보통 kaggle에 있는 bike share demand는 test 데이터셋의 label을 예측하는 것이기 때문에
전체적인 수치를 예측하는 것까지 나와있지 않다.
그러나, 나는 해당 사업을 진행하고 있는 기업이 나에게 예측 의뢰를 맡겼다는 컨셉을 잡았기 때문에
test label만 예측하기에는 뭔가 찝찝했다.
그래서 전체적인 bike share demand도 예측하는 모델링을 진행하였다.
train + 예측한 test 파일을 하나로 합쳐 비슷하게 모델링을 진행한게 전부이지만,
두 csv 데이터를 하나의 파일로 합치는 것을 학습한 것과 전체적인 bike 수요를 파악할 수 있었다는 차이점이 있다.
2. 그래서, 어쩌라고 ?!


'자전거 대여수 예측' 주제와는 벗어난 핵심적이지 않은 내용들.
주절주절 "저는 이런 것도 조사했어요!" = 열심히 하고자 하는 열정은 있으나 쓸데없음.
나의 목적은 "예측"이므로, 내가 디테일한 것까지 조사했다고 해서 다 보여줄 필요 없이 핵심만 잘 정리하면 됨.
분량이 많지 않고 발표 시간이 짧더라도 핵심만 알차게 구성되어 있으면 오히려 좋은 발표가 된다.
실제로 비즈니스 이해 부분에서 조잡한 설명이 너무 많았기 때문에
전수조사한 자료들이 아까웠지만 이 블로그에도 있고, 덕분에 몇개 안되지만 논문도 영어로 읽었다는 경험에 만족하며
주제에 대한 핵심 내용들을 뒷받침 할 근거로써 사용되지 않는 정보들은 과감히 날렸다.
그러나 수많은 정보들 사이에서 내가 전달하고자 하는 핵심 정보만 추려 정리하는 실력을 향상시킬 수 있었다는 점이
좋았던 것 같다.
실제로 위의 목차를 보면 확연히 줄었다는 것을 알 수 있다.
핵심 내용만 압축해서 전달하고자 노력하였고, 실제 ppt 구성을 보면 들어가야 할 내용들은 다 들어있다고 생각한다.

3. 그래서, 여기가 어디 파트인데?
추후에 이렇게 고쳤다.

4. 이건 왜 설명하는거지?

기본적으로 나는 ppt에 주절주절 글이 많은 것을 싫어한다.
ppt는 설명 중 가장 핵심적인 부분만 들어있어야 하며,
이미지나 간단한 타임라인 등 시각적인 효과를 강조해야 한다고 생각한다.
따라서 기본 입지 조건이 왜 필요한지에 대해서는 발표로 충당하였다.
해당 내용을 정리하기 위해 ppt의 발표자 노트를 활용하였다.
발표할 때 이 노트를 참고하여 설명하는 것은 나의 암기력의 몫임은 분명하다
5. 구체적인 데이터 설명 부재

처음에는 col 설명밖에 없었다.
그러나 각 파일마다 몇개의 col이 있고 총 몇개의 data가 있는지, data의 범위는 어디까지인지
구체적인 설명이 필요하다는 피드백을 받았다.
그래서 수정한 결과이다.
역시 나는 조잡한 글이 나열되어 있는 것을 싫어하기 때문에 조금 더 시각적으로 구분하기 편하게 수정하였다.

6. 필요없는 부분 삭제
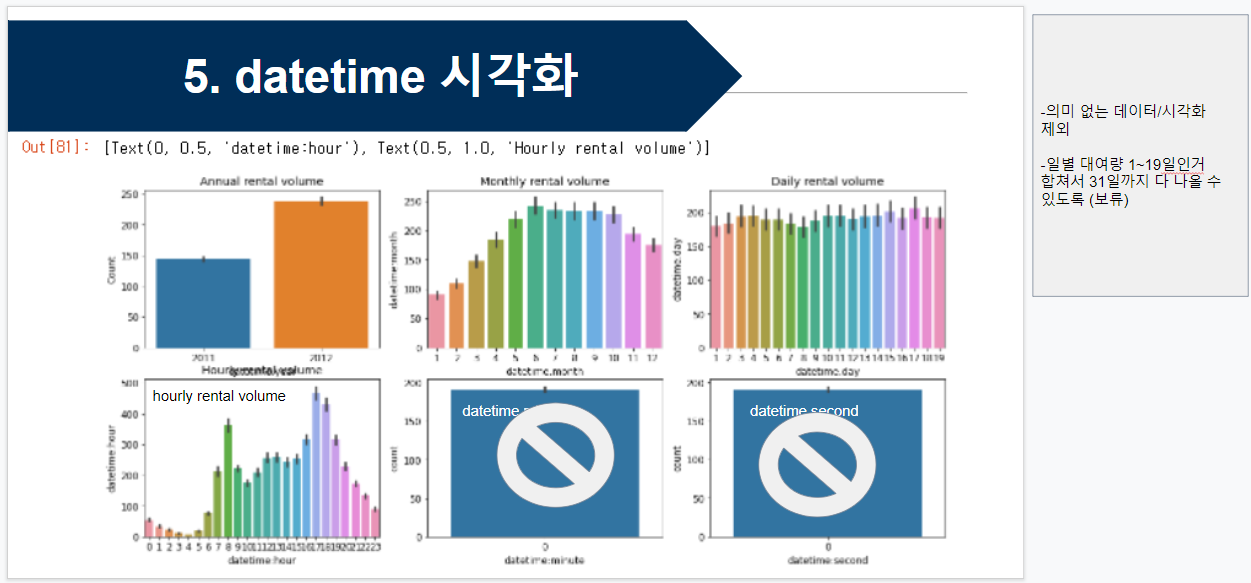
위 데이터의 시각화 부분에서 datetime : minute, datetime : second는 존재하지 않는 데이터로,
datetime을 분할 했을 때 나타났던 col이기 때문에 의미가 없다.
따라서 의미 없는 데이터를 굳이 시각화해서 보여줄 필요가 없는 것이다.
7. 그래서 결론은?

첫 발표는 EDA까지 진행했었다.
EDA까지 하고 feature engineering전까지의 결론은 결국,
전반적인 흐름에 대한 결론과 이 데이터들은 어떤 형태이며, 어떤 방법으로 모델링을 할 지의 내용이 있어야 한다.
결국 데이터 분석의 기본 이론 적용과 파악 능력이 중요하다.
나는 첫 발표 때 결론을 일반적인 대여수 추세에 대한 결론만 발표하였다.
EDA 뒤의 순서에 대한 향후 방법에 관한 고찰을 하지 않았고, 그것이 보여졌던 것 같다.
생각보다 비즈니스 이해 파트가 굉장히 시간이 오래 걸렸다.
해당 주제에 대한 EDA는 많이 나와있지만 비즈니스 이해를 실제로 하는 사람이 거의 없었기 때문에
내가 스스로 다 찾고 논리적으로 생각하고 근거를 들어 정리를 해야 했기 때문이었다.
누구의 도움도 없이 나 혼자 비즈니스 이해를 정리해야 했기 때문에 상당히 힘들었다.
내가 참고할 수 있는 거라곤 CRISP-DM 방법론 하나 뿐이었다.
그러나 피드백도 받고 나름 논리적으로 풀어가려 노력했는데
따로 업무도 하고 자격증 준비까지 해가면서 과제 한 것치곤 많이 늘었다고 생각한다.
2) Feature Engineering
1. Label값 정규화

- 왜 정규화를 시켜주었나?
- 정규화 방법은 sqrt말고도 log 변환 등 다른 방법이 있는데 왜 sqrt를 택했는가?
위 질문에 대해 충분히 고민해보는 시간이 있어야 할 것 같다.
아직 완벽한 대답은 준비가 되지 않았지만 정규화에 대해서 찾아보면서 대충 느낌을 알 수 있었다.
나중에 나는 log로 정규화를 진행해주었다.
Rapidminer로 log값을 취해주었는데, Jupyter Notebook으로도 나중에 코드를 한번 싹 바꿀 때 log값을 취해줄 예정이다.
왜냐하면 지금 원래의 label값인 count를 봤을 때 좌측으로 치우친 비대칭 데이터이므로 정규화가 필요하다.
한쪽으로 치우친 비대칭 데이터는 데이터의 품질이 낮을 가능성이 있기 때문이다.
정규화 방법으로는 대표적으로 box-cox, sqrt, log값을 취해주는 방법이 있는데,
내가 Rapidminer로 정규화를 시켜주었을 때는 sqrt보다 log값이 더 모델 성능이 좋게 나왔다.
box-cox도 나중에 한번 정규화를 시도해 볼 생각이다.
참고로 Rapidminer에는 [generate attributes] operator를 사용하여 log[(label col)+1] 수식을 입력해야 한다.
log는 최솟값이 1을 더해주어야 한다. 최솟값이 0보다 작을 수는 없기 때문이다.

2. 'windspeed' feature engineering - 평균 대체가 옳은 판단인가?

다른 사람들이 작성한 코드나 글 중 windspeed 관련하여 여러 가지의 방법이 있다.
a. 기존 데이터 그대로 반영
b. 0값을 결측값으로 취급, 평균값으로 대체
c. 0값을 결측값으로 취급, 모델링을 통해 0값을 예측하여 예측값으로 대체
d. feature 삭제
처음 나는 b의 방법을 썼었다.
하지만 풍속값에서 0값이 많다고 무작정 평균으로 대체했다가는 모델 결과에 왜곡이 일어날 수도 있다는 것이다.
다른 글에서 봤을 때는 풍속값의 0값이 많아 결측치를 0값으로 채워넣은 것 같다고 판단,
0값을 평균으로 대체하거나 모델링하여 예측한 값을 대체하는 등의 방법을 썼었다.
그러나 실제로 Washington DC에서 바람이 부는 날이 그 정도일 수도 있다.
따라서 다각적으로 살펴봐야하는데,
windspeed의 row data 17,379개 중 0값은 2,180개이므로, 전체의 약 12.5%를 차지하고 있다.
생각보다 0값을 평균으로 꼭 대체해야 할 만큼 결측치가 많은 수준이 아닌 것 같다.
또한 Label값인 count와 windspeed의 상관관계는 0.102로, 약한 상관관계를 띄고 있다.
다음은 실제로 Rapidminer에서 모델을 XGboost로 학습한 결과이다.
a. 0값을 결측값으로 취급, 평균값으로 대체 : R2 = 0.938
b. 기존 데이터 그대로 반영 : R2 = 0.962
c. feature 삭제 : R2 = 0.962
Python에서는 XGboost보다 lightGBM이 모델의 성능이 조금 더 좋았으나
Rapidminer에서는 lightGBM 모델을 다운받을 수 없어서 XGboost로 최종 학습을 하였다.
(linear regression, random forest, gradient boost, XGboost 총 4개의 학습 진행 결과, XGboost의 성능이 가장 우수하였다.)
확실히 windspeed의 0값을 평균값으로 대체하였을 때 R2의 성능이 가장 좋지 않았고,
0값을 살렸을 때와 feature를 삭제했을 때 모두 동일하게 R2의 성능이 높게 나왔다.
기존 데이터 그대로 반영한 것과 feature를 삭제했을 때 동일한 성능 수치가 나온 것은
내 생각에는 독립변수 windspeed와 종속변수 count가 약한 상관관계를 띄고 있기 때문이라고 생각한다.
windspeed가 count에 영향을 아주 약하게 미치기 때문에 모델의 최종 성능에 직접적인 영향을 끼치지 않는 것이다.
따라서 windspeed feature를 최종적으로 삭제하기로 결정하였다.
결론적으로 0값이 많다고 무작정 특정 값으로 대체하기 보다는
종합적으로 고려하여 최적의 결과를 만들어낼 때까지 신중하게 접근해야 한다는 것을 배웠다.
3. dummy coding은 integer로 바꾸는 것이 아니다 !

범주형 데이터는 integer이 아닌 nominal로 지정되어야 한다.
season의 봄, 여름, 가을, 겨울을 차례로 1 ~ 4로 지정하고 비교해봐도
봄 : 1 과 겨울 : 4를 따져봤을 때, 겨울이 봄보다 큰 수가 아니듯이.
season의 각 데이터들은 수치적으로 비교할 수 없는 명목형 변수들이다.
따라서 구분만 되어야 하는 게 맞다.
그러나 dummy coding을 해야 한다는 마음에 그만 integer로 형식을 바꿔버렸다.
회귀 모델을 돌릴 때는 수치로 이루어진 연속형 변수들만 가능하므로 명목형 변수는 포함되지 못한다.
따라서 명목형 변수까지 포함시키기 위해 dummy coding 즉,
명목형 변수들을 수치 형식의 값으로 매겨주어 연속형 변수같이 보이게 만들어준다.
그러나 수치로 비교할 수 있는 변수들은 아니다.
Rapidminer에서 직접 type을 바꿔보고 파라미터 값을 조정하다보니
이건 왜 이렇게 설정해야하지? 왜 내가 정한 값들이 틀렸지? 왜 왜곡이 발생하지?
이런 의문점들을 낳게 되고, 검색 및 질문을 통해서 답을 얻으니 뭔가 차근차근 알아가는 기분이다.
따라서 나는 이 명목형 변수들을 추후에 integer 형식이 아닌,
'Nominal to Numerical' Operator를 이용하여 coding type을 dummy coding으로 지정해주어
명목형 변수를 더미코딩하였다.

3) Modeling
1. 아무 모델이나 갖다붙이지 말자 !

Bike share demand prediction은 다중 회귀이다.
각 모델을 그냥 가져다가 돌리면 되는 줄 알았는데
이 모델이 무엇이고, 왜 사용하였는지 답하라는 물음에 척척 답할 수 없었다.
무조건 회귀 모델은 이러이러한게 있으니까 무턱대로 다 돌려보자 !
이런 마인드로 학습을 진행했다가는 본전도 찾지 못할 것이다.
최소한 이 모델의 기본 정보를 파악하고,
내가 진행하고자 하는 학습에 적합한 모델인지를 살펴봐야 할 것이다.

따라서 나는 cross validation을 기반하여
Linear Regression, Random forest, Gradient boost, XGboost 총 4개의 모델을 Rapidminer 상에서 학습시켰다.
[최종 반영 모델]
- linear regression
아직 Rapidminer에서 Ridge, Lasso, Elasticnet 세 모델을 구별하여 사용할 수 있는 Operator를 찾지 못했다.
그래서 linear regression으로만 진행하였다.
* 다중선형회귀는 여러 개의 독립변수를 이용해 종속변수를 예측, 일반 선형회귀보다 더 좋은 성능 기대 가능.
장점 : 다른 머신러닝 모델에 비해 상대적으로 학습이 빠르며 설명력이 좋다.
단점 : 선형모델의 특성상 underfitting이 쉽다.
- Random forest
overfitting 방지 위해 최적의 기준 변수를 랜덤하게 선택하는 머신러닝 기법.
랜덤으로 일부 feature만 선택하여 decision tree를 만들고 해당 과정 반복, 여러 개의 decision tree 형성,
여러 개의 decision tree에서 나온 예측값을 토대로 가장 많이 나온 값을 최종 예측값으로 산정.
앙상블 중 bagging 기법 이용하여 구현.
장점 : overfitting 문제 최소화, 모델 정확도 향상.
대용량 데이터 처리에 효과적.
- Gradient boosting
학습 기법으로 병렬처리가 어려워 XGboost보다 상대적으로 진행속도 느림.
약한 예측 모델 중 하나.
여러 개의 약한 학습기를 순차적으로 학습 및 예측하면서 잘못된 데이터에 가중치 부여를 통해
오류를 개선해 나가면서 학습하는 방식.
decision tree를 약한 학습기로 사용.
best first방식으로 가지 뻗쳐나감, information gain이 없다면 굳이 가지 뻗침x
- XGboost
여러 개의 decision tree 이용한 앙상블 모델 (boosting방법)
gradient boosting 대비 빠른 수행시간 가짐, 아주 효율적인 예측 성능 발휘
(+분류 영역에서도 마찬가지)
병렬처리 -> 수행시간 빠름
max depth까지 분할 후 이득 없는 가지 쳐냄.
[삭제 모델]
- K-Nearest Neighbor (KNN)
주변 가장 가까운 k개의 샘플을 통해 값을 예측하는 방식.
1~100의 데이터셋으로 모델 학습 진행 완료하였으나,
1000의 데이터셋으로 예측을 진행하고자 한다면 100에서 가장 가까운 값으로 예측하고자 할 것이다.
따라서 본 회귀문제에 대해서 정확도가 높지 않을 것이라 판단, 삭제해주었다.
- Decision tree
supervised learning에 해당한다.
Output variable이 연속적인 값일 경우(월급, 몸무게) 회귀를 사용한다.
overfitting이 될 가능성이 높다는 단점이 있다.
가지치기를 통해 max depth 설정 가능하나, 이로써는 overfitting을 충분히 해결할 수 없다.
(-> 보완되어 나온 모델이 Random forest이다.)
따라서 삭제해주었다.
-Catboost & LightGBM
삭제하고 싶지 않았으나 Rapidminer에서 아직 업데이트 되지 않은 모델이라
눈물을 머금고 삭제하였다.
추후 Jupyter Notebook에서 여태 진행했던 내 초라한 모델 학습들을 갈아엎을 예정인데,
그때 catboost와 lightgbm을 포함시켜 진행할 예정이다.
2. 성능 지표는 어떻게 해석하는가?

성능 지표는 총 4개로 채택하였는데,
처음에는 뭣도 모르고 모든 사람이 이런 지표를 채택하여서 나도 따라한 것이었다.
물론 capital bike share demand는 RMSLE의 성능 지표를 채택하고 있지만,
처음 Train 데이터셋을 통해 test 데이터셋의 label 값을 예측할 때, 즉 kaggle에 제출할 때만 이 성능지표를 사용하고
train + test 데이터셋을 합친 온전한 2011 - 2012 데이터셋을 통하여 전체를 예측하는 모델의 학습을 진행할 때는
mean square error, root mean square error, r^, adjusted r^ 총 4개의 성능지표를 택하였다.
-MSE(Mean Square Error)

실제값과 예측값의 편차에 제곱의 합을 구한 후 평균 구한 값.
데이터의 양이 많아서 값이 커지는 것인지, 실제 오차가 커서 값이 커지는 것인지 구분 가능하다.
(오차제곱합인 SSE와의 차이점이다.)
주로 회기 분석에서 모델의 적합도를 판단할 때 사용하는 값인 결정 계수(R^)를 계산할 때 분자로 사용된다.
주식 가격 예측과 같은 연속형 데이터를 사용할 때 사용.
이상치에 민감.
accuracy와는 다르게 실제 정답값과 얼마 정도의 오차율을 가지고 있는지 알려주는 값.
알고리즘이 정답을 잘 맞출 수록 mse값은 작다.
mse = 0.15 라면 평균이 15%정도 오차가 있다는 뜻이다.
-RMSE(Root Mean Square Error)
mse보다 이상치에 덜 민감하다. (mse의 단점 보완)
mse의 값에 루트를 씌운 값이다.
rmse = 1.5206... 일 때
실제값 대비 예측값에서 1.5정도의 오차가 발생한다는 의미이다.
MAE와 함께 가장 일반적으로 많이 쓰이는 회귀모델 성능지표다.
*MAE(Mean Absolute Error)
모델의 예측값과 실제값의 편차의 값에 절대값으로 변환하여 평균을 구한 것.
에러에 절대값을 취하기 때문에 오차율의 크기 그대로 반영한다.
에러에 따른 손실이 선형적으로 올라갈 때 적합한 성능지표이며,
이상치가 많을 때 사용하기 적합하다.
(bike share demand 데이터에는 이상치가 많지 않기 때문에 해당 성능지표를 반영하지 않았다.)
-R^ (R2, R square)
결정계수 R2의 최댓값은 1이며, 이 수치가 클수록 실제값과 예측값이 유사함을 의미.
R2 = 0.7935... 일 때
모델링한 해당 모델은 약 0.79의 결정계수를 가지며
이는 독립변수들이 종속변수에 미치는 영향이 79%로,
독립변수들이 종속변수값 변동의 79%를 설명할 수 있다는 뜻이다.

3. 모델링만 하면 되는가?
모델링만 하면 일반화된 모델링이 아닌,
해당 데이터셋에만 국한된 모델이 된다.
따라서, 모델을 사용하기 전에 train과 test로 데이터셋을 나누고,
교차검증 Operator를 사용하면 좋다.

모델의 일반화 및 overfitting을 방지하기 위해 교차검증을 실시하는
cross validation operator를 사용하였다.
그저 남들이 만든 결과물을 보고 따라하며 이해하는 것도 학습이 아예 되진 않겠지만
왜 이런 것들을 사용하였을까?
이것들을 사용함으로써 얻는 이점이 무엇인가?
이것들의 정체는 무엇인가?
다른 관점에서 봤을 때도 타당한 결론인가?
이러한 질문을 스스로에게 끊임없이 되물으며 한 결과물을 오롯이 이해하려는 습관이 정말 중요한 것 같다.
꼬리에 꼬리를 무는 질문을 통해
조금 더 깊이 학습하려는 자세를 배운 것 같다.
더불어 얕은 지식이나마 얻게 되면서
앞으로의 내가 학습할 것들에 대해서 익숙해지고 있는 것 같아서 좋았다.
그저 결과물만 따라서 하면 된다고 생각했는데
생각해야 할 것들도 많고, 알고 있어야 하는 기본 지식들도 적지 않은 것 같다.
누구나 다 만들 수 있는 쉬운 모델링이나
test의 label값 예측하는 모델만 만드는 것이 아닌,
거의 대부분의 사람들이 시도하지 않은 train + test 데이터를 취합해 완전한 데이터로
다시 예측을 시도하는 것 자체가 나에게는 도전적인 일이었음은 분명하다.
또한 데이터 분석을 함에 있어서 정해진 결과가 있는 것만이 아닌,
아무리 쉽고 간단한 데이터라도 사람마다 해석하기에 다르다는 것이 많은 것을 생각하게 만든다.
나는 a의 방법을 쓰면 될 것 같아서 독단적으로 a를 쓰는 것 보다는
다른 사람들의 의견도 들어보고 타당한 근거를 찾으면서 분석을 진행하려고 노력하는 자세가 가장 중요하다.
쉬운 모델을 모델링 하더라도 내 의견과 생각이 묻어있는 모델을 학습하려고 노력해야한다.
Capital bike share demand 프로젝트도 1인 프로젝트지만
여기저기서 도움도 많이 주고 자문도 구하면서 다양한 것들을 알게 되었다.
이번에 Jupyter Notebook으로 새롭게 생각한 것들과 수정한 것들을 반영하여 다시 모델링해봐야겠다.
처음으로 깃허브도 커밋해야지
'[Data Science] > Data Analysis' 카테고리의 다른 글
| [Capital bike share demand] Error (0) | 2022.05.11 |
|---|---|
| [Python/Jupyter Notebook]CSV 파일 합치기 (0) | 2022.05.09 |
| [Bike Sharing Demand]비즈니스 이해 - 자전거 공유 시스템 (0) | 2022.04.27 |
| [Kaggle]Capital Bike Sharing (0) | 2022.04.26 |
| [Bike Sharing Demand]비즈니스 이해 - Washington D.C. Weather (0) | 2022.04.22 |